
I don’t know exactly when this happened (my best guess is maybe sometime in April, based on this YouTube video; if you watch it, be aware that the output seems to have improved since it was made), but at some point in the not-too-distant past, Google Docs has started including accessibility tags in downloaded PDFs. And while not perfect, they don’t suck!
update: Looks like this started rolling out in December 2024, earlier than I realized. Thanks to Curtis Wilcox for pointing out the announcement link.
Quick Background
For PDFs to be compatible with assistive technology and readable by people with various disabilities, including but not at all limited to visually disabled people who use screen readers like VoiceOver, JAWS, NVDA, and ORCA, PDFs must include accessibility tags. These are not visible to most users, but are embedded in the “behind the scenes” document information, and define the various parts of the document. Assistive technology, rather than having to try to interpret the visual presentation of a PDF, is able to read the accessibility tags and use those to voice the document, assist with navigation, and other features.
However, until recently, Google Docs has not included this information when exporting a PDF using the File > Download > PDF Document (.pdf) option. PDFs downloaded from Google Docs, even if designed with accessibility features such as headings, alt text on images, and so on, were exported in an inaccessible format (as if they had been created with a “print to PDF” function). The only way around this was to either use other software to tag the PDF or to export the document as a Microsoft Word .docx file and export to PDF from Word.
But that’s no longer the case! I first realized this a couple months ago when I was sent a PDF generated from Google Docs and was surprised to see tags already there. I’ve recently had the chance to dig into this a little bit more, and I’m rather pleasantly surprised by what I’m seeing. It’s not perfect, but it doesn’t suck.
Important note
I’m not a PDF expert! I’ve been working in the digital accessibility space for a bit over three years now, but I’m learning more stuff all the time, and I’m sure there’s still a lot I don’t know. There are likely other people in this space who could dig into this a lot more comprehensively than I can, and I invite them to do so (heck, that’s part of why I’m making this post). But I’m also not a total neophyte, and given how little information on this change I could find out there, I figured I’d put what knowledge I do have to some use.
Testing process
Very simple, quick-and-dirty: I created a test Google Doc from scratch, making sure to include the basics (headings, descriptive links, images with alt text) and some more advanced bits (horizontal rules, a table, a multi-column section, an equation, a drawing, and a chart). I then downloaded that document as a PDF and dug into the accessibility tags to see what I found. As I reviewed the tags, I updated the document with my findings, and downloaded a new version of the PDF with my findings included (338 KB .pdf).
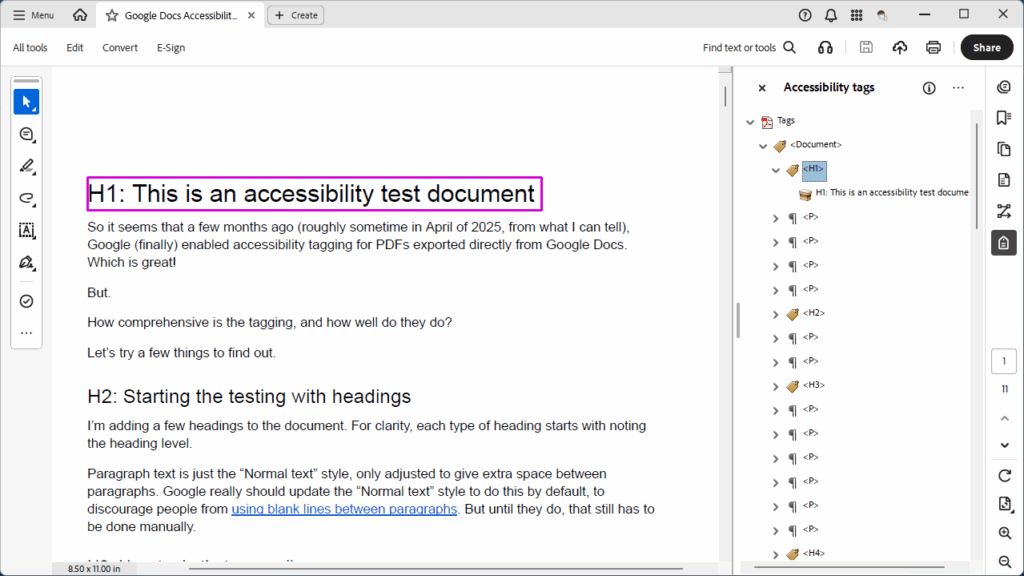
Findings
More details are in the PDF, but in brief:
- Paragraphs are tagged correctly as
<P>. - Heading are tagged correctly as
<H1>(or whatever level is appropriate). - Links are tagged correctly as a
<Link>with a<Link - OBJR>tag. Link text is wrapped in a<Span>, and the link underline ends up as a non-artifacted<Path>. - Images are tagged correctly as a
<Figure>with alt text included. However, images on their own lines end up wrapped inside a<P>tag and are followed by a<Span>containing an empty object (likely the carriage return). - Lists are pretty good. If a
<LI>list item includes a subsidiary list, that list is outside of the<LBody>tag, and I’m not sure if that’s correct, incorrect, or indifferent. Additionally, list markers such as bullets or ordinals are not wrapped in<LBL>tags but are included as part of the<LBody>text object. However, this isn’t unusual (I believe Microsoft Word also does this), and doesn’t seem to cause difficulties. - Tables are mostly correct, including tagging the header row cells with
<TH>if the header row is pinned (which is the only way I could find to define a header row within Google Docs). However, the column scope is not defined (row scope is moot, as there doesn’t seem to be a way to define row header cells within Google Docs; the table options are fairly limited). - Horizontal lines are properly artifacted, but do produce a
<P>containing an empty object (presumably the carriage return, just as with images). - Using columns didn’t affect the proper paragraph tagging; columned content will be read in the proper order.
- Inserted drawings and charts are output as images, including any defined alt text.
- Equations are just output as plain text, without using MathML, and may drop characters or have some symbols rendered as “Path” within the text string. STEM documents will continue to have issues.
Conclusion
So, not perfect…but an impressive change from just a few months ago, and really, the output doesn’t suck! For your basic, everyday document, if you need to distribute it as a PDF instead of some other more accessible native format, PDFs downloaded from Google Does now seem to be a not-horrible option. (My base recommendation is still to distribute native documents whenever possible, as they give the user agency over the presentation, such as being able to adjust font face, size, and color based on their needs. However, since PDFs are so ubiquitous, it’s heartening to see Google improving things.)