With the release of Affinity by Canva, I was curious how they were doing on supporting creating accessible PDF output. A very quick cursory initial check showed some hopeful signs, but I wanted to take a more detailed look, so I’ve put together a brief test document to check some of the more common document features. This isn’t at all meant to be all-encompassing and comprehensive; it’s just what popped to mind as I was experimenting. My hope is to occasionally update this as I think of more test cases (or have more test cases suggested to me) and as Affinity is updated.
More details are in the document itself, but in brief, I set up several test cases using various Affinity features, exported to tagged PDF, and checked the PDF in Acrobat to see how things looked.
If you’d like to play along at home, you can download the source .af document (5 MB .zip) and the exported .pdf document (721 KB .pdf) to review yourself and otherwise do with as you wish under a Creative Commons BY 4.0 license.
The executive summary TL;DR: Canva/Affinity is making improvements, but Affinity in its current state is definitely not ready to be a replacement for Adobe InDesign. If you’re an Affinity die-hard and have the time and resources to do remediation work in Acrobat Pro or using a tool like CommonLook, you could certainly go that route, but don’t expect to be able to export an accessible PDF from Affinity just yet.
1/15/2026 Update: Testing with Affinity v3.0.2.3912 reveals no improvements and one regression.
I do want to be clear that none of this is to say that Affinity is “bad” or shouldn’t be used; on the contrary, I’m looking forward to using it as much as I can (for experimentation and any print-only work I do). This is all intended to encourage Canva/Affinity to continue working on this aspect of their software.
Test Case 1: Paragraphs
Result: Fail. Any paragraph that is more than one line gets one P tag for every line, rather than one P tag for the entire paragraph. In addition, if there are any deviations from the base style (using character styles, manual formatting, adding hyperlinks, etc.), all of those end up in their own individual P tags instead of being wrapped in Span tags inside the P tag.
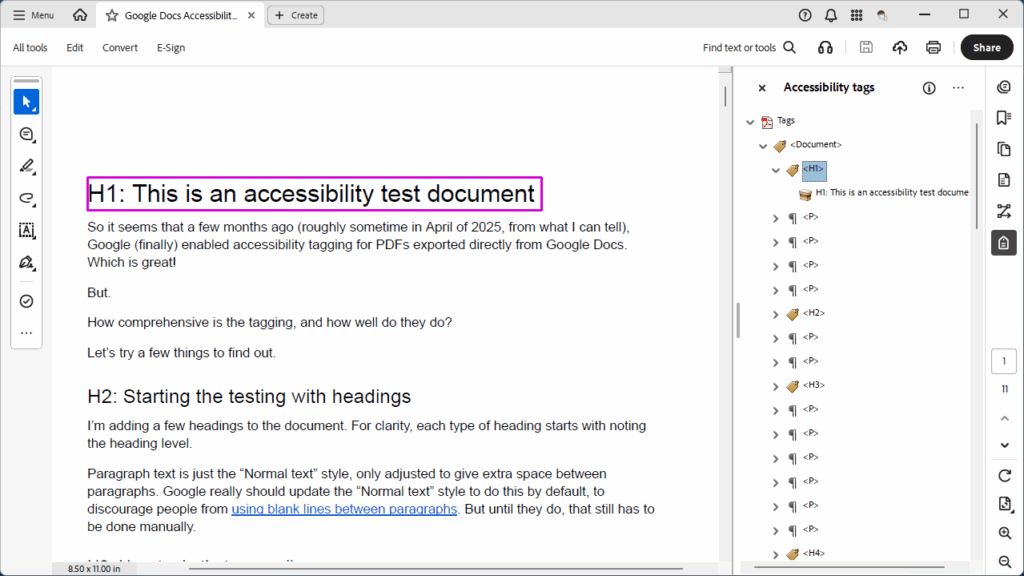
Test Case 2: Headings
Result: Pass (with qualifications). When creating styles, PDF (and EPUB) export tagging can be assigned — as long as you only need P or H1 through H6; no other tags (like BlockQuote, for example) can be assigned to styles. Within that, though, text given a heading style does export with the correct tag…but once again, if the heading spans more than one line, it ends up being two H1 (or whatever level) tags rather than one.
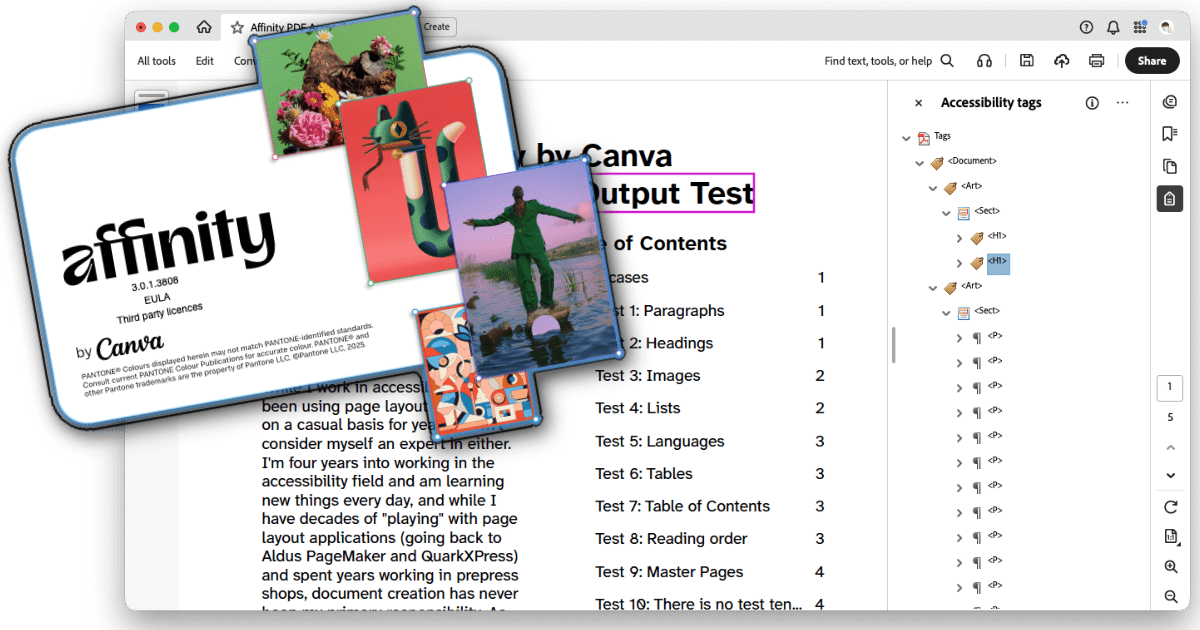
Test Case 3: Images
Result: Pass/Fail (yes, both).
Pass: Images can be placed inline or floated; if floated, they can be anchored within text. Alt text can be assigned various ways, either manually or (in theory, I didn’t test this) automatically pulled from the image’s XMP metadata. The alt text pane also supports adding extended description and summary text, though I haven’t played with these fields yet. Alt text is correctly added to the Figure tag in the PDF.
Fail: Though the images were placed inline with the text in the document, the Figure tag was placed at the end of the content for its parent text frame rather than at the proper place within the text.
Test Case 4: Lists
Result: Fail. Lists are tagged as paragraphs, without any L or child LI, LBL, or LBODY tags.
Test Case 5: Languages
Result: Fail. I could not find any way to designate a base language for the document as a whole. Character and paragraph styles can be given a language setting, but (in addition to the character style being tagged as a new P rather than a Span within the paragraph) the language is not set in the tag properties.
Test Case 6: Tables
Result: Fail. Simple tables can be added and their visual presentation can be adjusted, but I found no way to set header rows or columns. Tables also cannot be given alt text (at least, not with the same Tags pane used to add alt text to images).
The table was not tagged with any Table or child TR, TH, or TD tags, just a lot of P tags. In addition, though the table was inline with text later in the document, it was placed as a Sect at nearly the top of the document, the first tags underneath the opening H1 tags.
Test Case 7: Table of Contents
Result: Fail. Affinity can automatically generate a table of contents from the header styles used in a document. However, the exported PDF does not use any TOC or associated child tags; every line of the table of contents is a P tag followed by a Link tag that contains two Link - OBJR tags, one for the text of the item and one for the page number.
Test Case 8: Reading Order
Result: Pass (with qualifications). Affinity has a Reading Order panel which allows you to rearrange items, group items together into articles, and toggle items off and on, and this does properly affect the tags in the exported PDF. In an earlier test document (not publicly distributable), I was easily able to put all of the objects in their correct reading order. However, in this test document, the images (which are placed inline with the text, and therefore within a text frame) don’t appear in the reading order panel, and as noted above, don’t have their Figure tags placed in the correct location.
Test Case 9: Master Pages
Result: Pass. My test document had master pages set up with footer text; this text was properly excluded (artifacted) in the PDF.
Test Case 10: There is no test ten…
…because I ran out of ideas right then. But more can be added! When I have time, I want to add more objects to play with the reading order pane more, explore Affinity’s footnotes/index/reference support (which at this point I don’t expect to be tagged correctly, but maybe someday), and there are probably plenty of other things that more experienced accessibility and/or document creation professionals might think of.
Conclusion
As noted in the TL;DR up top, Affinity is a long way away from being able to replace InDesign when it comes to creating accessible PDFs.
That said — they’re working on it! This is more support than the last version of Affinity had, and there are more signs here and there that more may be in development. For example, while I was looking for a way to specify a base document language, I checked the File > Document Metadata option, and it’s a series of checkboxes and fields for specifying exactly which accessibility features a document supports, its conformance level, a certifier’s name and credentials, and so on. (The actual basic document metadata, including title, author, copyright info, etc., can be set with the Window > References > Fields pane, and does get properly added to the exported PDF.)
While there’s certainly work to be done, I’m encouraged to see the features that have been added so far, and as noted above, want to encourage Affinity to continue working on this aspect of the app. I would love to be able to finally drop InDesign (as I dropped Photoshop and Illustrator years ago) and move entirely over to Affinity (well…entirely aside from Acrobat…).
Addendum: ePub output
Out of curiosity and a question on Mastodon (that I don’t actually think was directed at me, but that’s okay), I exported this test document to ePub format, using both the “fixed layout” and “reflowable” options. I then checked each file in both Thorium Reader and Apple’s Books app, and ran them through the Ace by DAISY ePub accessibility checker.
It should be noted that I did not change anything about the file for this test, and I created the document with PDF in mind, not ePub, so this may affect the results.
I’m not as experienced in checking ePub files, but a few notes:
Ace by DAISY reported errors with both documents. The fixed layout version had eight errors, three serious and five moderate; the reflowable version had 22 errors, one critical, 16 serious, and five moderate. The ePubs and Ace by DAISY reports may be downloaded for you to review. All downloadable files are .zip files that you’ll need to decompress — I know that ePubs are already zipped, but my WordPress configuration wouldn’t allow me to upload the .epub file.
The fixed layout version is much larger than the reflowable. I think that’s because the reflowable version seems to have scaled and compressed the photos in the document, while the fixed layout version left them at their original sizes. This may have been an export setting in Affinity that I didn’t adjust.
Neither document has bookmarks automatically defined.
The fixed layout version in Thorium using Thorium’s built-in reader reads the images outside of their placement in the text, instead speaking them at the beginning of the second page. The table on page three also gets read at the beginning of the third page. This does not happen with the reflowable version; images are read in their correct locations.
There’s an odd black square graphic that appears at the end of the Test 3 section in the reflowable version that is not present in the original Affinity file. I have no idea where this image is coming from.
Using Apple Books’s built-in reader, the reflowable version seemed to read properly, but the fixed layout version was missing large chunks of text.
With the aforementioned caveat that this document wasn’t created with ePub in mind, which may be affecting things, my first impression is that, as with PDF tagging, Affinity has some work to do with creating accessible ePub files. This is definitely an app that currently is much more aimed at visual presentation (whether print or electronic), with accessibility being an afterthought. Once again, I hope this improves over time as future versions are released.




![Screenshot of a section of a website form. On the left is an option to upload a logo image, on the right is a text box asking for alt text. The prompt reads, 'A brief description of the image to support our Blind and low vision members. If no alt text is provided, '[display name] logo' will be used.' The field is limited to 1000 characters.](https://michaelhans.com/eclecticism/wp-content/uploads/2025/07/Screenshot-2025-07-01-at-9.13.55PM.png "Screenshot 2025-07-01 at 9.13.55 PM.png")




